anomalyDetectorExtremeValues
Detects subsets of contiguous values that are anomalous because all values in the subset are extremely high or extremely low. You might use this function to identify periods in which all monthly sales totals are extremely high.
An extreme value is one that is more than the threshold percentage above standard deviation distance from the mean of the whole series. Values that are not extreme are deemed normal.
The result is a list of ATL objects, one for each detected subset of extreme values. The object gives the start and end dates for the subset, information about the extreme values, and other details that may be useful. See Result object fields for a full breakdown. The function returns an empty list if there are no anomalies — that is, no subsets of extreme values.
The function aggregates and compares data at the selected level of time granularity (daily, monthly, or quarterly). The function uses sum aggregation by default, but you can select a different type by using the function's optional parameter.
Parameters
SERIES (list)
The input series of numbers. This must be a list or list-like object (e.g. a column or row) containing numbers.
DATES (list)
A list of dates, one for each number in the input series. This must be a list or list-like object containing datetime objects, or strings in the 'yyyy-MM-dd' pattern.
TIME GRANULARITY (string)
The granularity at which the data is compared. The options are daily, monthly, or quarterly.
THRESHOLD PERCENTAGE (number)
The percentage above standard deviation distance from the mean that values must be to count as extreme. For example, a value of 50 sets the threshold to 150% of the standard deviation, so all values in a contiguous subset must be that much above or below the mean for the subset to be anomalous.
WINDOW SIZE (number)
The minimum number of values required for a subset to qualify as an anomaly. Must be an integer value >= 2.
AGGREGATION FUNCTION (function)
Optional. The function used to aggregate values within the same time granularity period. The options are sum(), mean(), maxVal(), minVal(), or count(). Sum aggregation applies by default.
Default: sum()
Notes
The function removes null values from SERIES (and corresponding values in DATES) before performing its analysis.
The function removes null values from DATES (and corresponding values in SERIES) before performing its analysis.
If SERIES and DATES are of unequal length, the function truncates the longer list to ensure lists of equal length.
The input to THRESHOLD PERCENTAGE must be a non-negative number.
Result object fields
The function returns an ATL object for each detected anomaly — that is, each subset of extreme values.
Each result object contains these fields:
Field | Description |
|---|---|
startDate | The start date for the subset. |
endDate | The end date for the subset. |
startValue | The first value in the subset. |
endValue | The last value in the subset. |
anomalyRange | This is always time series for anomalies detected by this function. |
anomalyCategory | This is always collective for anomalies detected by this function. |
anomalyType | This is always extreme for anomalies detected by this function. |
anomalyClass | Indicates whether the anomaly is high, low, or mixed. |
maxValue | The highest value in the subset. |
maxValueDate | The date for the highest value in the subset. |
minValue | The lowest value in the subset. |
minValueDate | The date for the lowest value in the subset. |
nearestNormalValue | The normal (non-extreme) value in the series that is nearest (in value) to the values in the subset. |
nearestNormalDate | The date for the nearest normal value (see above). |
normalMean | The mean of all normal values in the comparison group. |
normalStdDev | The standard deviation for all normal values in the comparison group. |
Important
The function aggregates and compares data at the selected level of time granularity, so the value for fields such as startValue, maxValue, nearestNormalValue, etc. is an aggregated value. See the examples for further guidance.
Examples
Example 1 — monthly granularity
This example uses a dataset that is far too large to display fully here. Instead, we've uploaded the data into THIS DOWNLOADABLE PROJECT. The project contains no script content, so you can copy-paste in the example ATL and try it yourself.
The full dataset contains sales data for 2020 and 2021. For reference, the first six rows are:
ID | Date | Day | Month | Quarter | Year | Sales | |
|---|---|---|---|---|---|---|---|
Row 1 | 1 | 2020-01-02 | 2 | Jan | Q1 | 2020 | 5,000.00 |
Row 2 | 2 | 2020-01-11 | 11 | Jan | Q1 | 2020 | 4,000.00 |
Row 3 | 3 | 2020-01-23 | 23 | Jan | Q1 | 2020 | 3,000.00 |
Row 4 | 4 | 2020-02-04 | 4 | Feb | Q1 | 2020 | 6,000.00 |
Row 5 | 5 | 2020-02-08 | 8 | Feb | Q1 | 2020 | 2,000.00 |
Row 6 | 6 | 2020-02-17 | 17 | Feb | Q1 | 2020 | 5,000.00 |
Suppose you want to look for periods (three months minimum) in which each monthly sales total is an extreme value. Also, suppose an extreme value is one 30% higher or lower than usual, allowing for normal variation as measured by standard deviation.
The ATL [[anomalyDetectorExtremeValues(Sales, Date, 'monthly', 30, 3)]] returns this result:
|
The results list contains two ATL objects, one for each anomalous subset. You can tell from the anomalyClass values that one anomaly is high and the other is low. The result is easier to understand by looking at this table of aggregated totals:

The high anomaly comprises a three-month period from Jun 2020 to Aug 2020. Each aggregated total in this subset is extremely high. Similarly, the low anomaly comprises a period from Feb 2021 to Apr 2021 and each total in that subset is extremely low.
Here's how you might extract values from the result to produce narrative text:
[[ results = anomalyDetectorExtremeValues(Sales, Date, 'monthly', 30, 3) highOnly = filter(results, x -> x.anomalyClass == 'high')[0:1] lowOnly = filter(results, x -> x.anomalyClass == 'low')[0:1] highStartDate = map(highOnly, x -> "[[formatDateTime(x.startDate, 'MMM yyyy')]] ([[abbreviateNumber(currencyFormat(x.startValue))]])") highEndDate = map(highOnly, x -> "[[formatDateTime(x.endDate, 'MMM yyyy')]] ([[abbreviateNumber(currencyFormat(x.endValue))]])") lowStartDate = map(lowOnly, x -> "[[formatDateTime(x.startDate, 'MMM yyyy')]] ([[abbreviateNumber(currencyFormat(x.startValue))]])") lowEndDate = map(lowOnly, x -> "[[formatDateTime(x.endDate, 'MMM yyyy')]] ([[abbreviateNumber(currencyFormat(x.endValue))]])") normalAvg = unique(map(results, x -> x.normalMean)) "Monthly sales were extremely high from [[highStartDate]] to [[highEndDate]] and extremely low from [[lowStartDate]] to [[lowEndDate]]. Excluding the anomalous periods, average monthly sales were [[abbreviateNumber(currencyFormat(normalAvg))]]." ]]
The output text is:
Monthly sales were extremely high from Jun 2020 ($26K) to Aug 2020 ($28K) and extremely low from Feb 2021 ($4K) to Apr 2021 ($3K). Excluding the anomalous periods, average monthly sales were $12.2K.
NOTE ON QUARTERLY GRANULARITY
If you ran a similar analysis but with the TIME GRANULARITY parameter set to quarterly, the function would return an empty list. You can try this in the downloadable project using this ATL: [[anomalyDetectorExtremeValues(Sales,Date,'quarterly',30,3)]].
It's easier to understand the result (no anomalies) by looking at this table of aggregated totals:
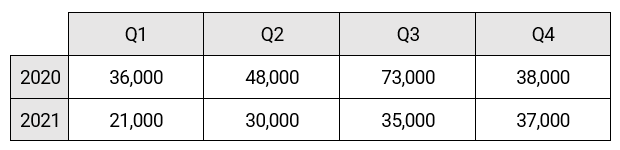
Remember that the WINDOW SIZE parameter is set to 3. The total for Q3, 2020 (73,000) stands out as extremely high, but it's not detected as an anomaly because it's a single value. As per the ATL, function looks for sets of three or more extreme values.
Tip
To detect single values that are extremely high or extremely low, use anomalyDetectorContextual instead.
Example 2 — Daily granularity
Assume a "Describe the Table" project with this data:
ID | Date | Day | Month | Quarter | Year | Sales | |
|---|---|---|---|---|---|---|---|
Row 1 | 1 | 2021-02-01 | 1 | Feb | Q1 | 2021 | 9,000.00 |
Row 2 | 2 | 2021-02-02 | 2 | Feb | Q1 | 2021 | 8,000.00 |
Row 3 | 3 | 2021-02-03 | 3 | Feb | Q1 | 2021 | 10,000.00 |
Row 4 | 4 | 2021-02-04 | 4 | Feb | Q1 | 2021 | 8,000.00 |
Row 5 | 5 | 2021-02-05 | 5 | Feb | Q1 | 2021 | 7,000.00 |
Row 6 | 6 | 2021-02-06 | 6 | Feb | Q1 | 2021 | 19,000.00 |
Row 7 | 7 | 2021-02-07 | 7 | Feb | Q1 | 2021 | 22,000.00 |
Row 8 | 8 | 2021-02-08 | 8 | Feb | Q1 | 2021 | 1,000.00 |
Row 9 | 9 | 2021-02-09 | 9 | Feb | Q1 | 2021 | 2,000.00 |
Row 10 | 10 | 2021-02-10 | 10 | Feb | Q1 | 2021 | 8,000.00 |
Row 11 | 11 | 2021-02-11 | 11 | Feb | Q1 | 2021 | 10,000.00 |
Row 12 | 12 | 2021-02-12 | 12 | Feb | Q1 | 2021 | 9,000.00 |
Row 13 | 13 | 2021-02-13 | 13 | Feb | Q1 | 2021 | 8,000.00 |
Row 14 | 14 | 2021-02-14 | 14 | Feb | Q1 | 2021 | 10,000.00 |
The table contains sales data for the first two weeks of Feb 2021. Typically, you would have sales data covering a longer period, but we've kept the dataset small to simplify the example. Use THIS DOWNLOADABLE PROJECT if you want to try the example yourself.
Suppose you want to look for periods (three days minimum) in which each daily sales total is an extreme value. Also, suppose an extreme value is one 30% higher or lower than usual, allowing for normal variation as measured by standard deviation.
The ATL [[anomalyDetectorExtremeValues(Sales, Date, 'daily', 30, 3)]] returns this result:
|
The results list contains a single ATL object. The anomalyClass value is mixed, which means the subset contains a mix of extremely high values and extremely low values. The result is easier to understand by looking at this table of aggregated totals:

The anomaly comprises a four-day period from Feb 6, 2021 to Feb 9, 2021. As you can see, there are two extremely high values and two extremely low values. Note that the highest and lowest values (22,000 and 1,000) are provided in the result object.
Here's how you might extract values from the result to produce narrative text:
[[ results = anomalyDetectorExtremeValues(Sales, Date, 'daily', 30, 3) mixedOnly = filter(results, x -> x.anomalyClass == 'mixed')[0:1] startDate = map(mixedOnly, x -> x.startDate) endDate = map(mixedOnly, x -> x.endDate) maxValDetails = map(mixedOnly, x -> "[[x.maxValueDate]] ([[abbreviateNumber(currencyFormat(x.maxValue))]])") minValDetails = map(mixedOnly, x -> "[[x.minValueDate]] ([[abbreviateNumber(currencyFormat(x.minValue))]])") normalAvg = abbreviateNumber(currencyFormat(map(mixedOnly, x -> x.normalMean))) "Daily sales were either extremely high or extremely low from [[startDate]] to [[endDate]]. The highest sales total in this period was on [[maxValDetails]] and the lowest was on [[minValDetails]]. Excluding the anomalous period, average daily sales were [[normalAvg]]." ]]
The output text is:
Daily sales were either extremely high or extremely low from Feb 6, 2021 to Feb 9, 2021. The highest sales total in this period was on Feb 7, 2021 ($22K) and the lowest was on Feb 8, 2021 ($1K). Excluding the anomalous period, average daily sales were $8.7K.
Note
All examples above use sum aggregation, which applies by default. Remember that you can pick a different aggregation type — e.g. mean or count — using the optional parameter.
