Subject-verb agreement
Note
This section of the tutorial is also available as a downloadable project.
Subject-verb agreement is the agreement between the subject and the main verb in a sentence. For example, an "s" is usually added to a present tense verb with a singular subject — e.g. "He eats four apples." No "s" is added with a plural subject — e.g. "They eat four apples."
You can, of course, add functions to handle subject-verb agreement in your ATL script. Alternatively, you can write a lex rule that handles subject-verb agreement automatically. We show you how to do both below.
Subject-verb agreement in ATL
In ATL, you can write sentences using the inflectVerb function:
ATL in Script | Result |
|---|---|
| John eats two apples. |
| John and Carol eat one apple. |
The first sentence uses the default singular verb inflection, but in the second we have changed inflectVerb manually (using the function's optional parameters) to get subject-verb agreement.
To automate the choice between singular and plural in ATL, we need to add a conditional to test whether the subject of the sentence has more than one name. Let's make the subject of the sentence a variable called People, which is a list of people's names. We would then write the conditional as follows:
[[ if(len(People)>1) {[[inflectVerb('eat','plural','','')]]}else{[[inflectVerb('eat','singular','','')]]} ]]
If the variable Person is a list of one name (e.g. John) and the variable People is a list of two names (e.g. John and Carol), you can see the operation of the conditional produces output with the correct verb inflections:
ATL in Script | Result |
|---|---|
| John eats two apples. |
| John and Carol eat one apple. |
Subject-verb agreement with lex rules
Lex rules handle subject-verb agreement automatically.
Lex rules are contained in XML files and can be imported into your project using the Lex Rules View. For more information about lex rules files, see Language functions > realise > Lex rules files.
The lex rule used for the following examples is already set up in the downloadable Subject-Verb Agreement JSON project (see the link at the top of this page). However, for easy reference, the full lex rules file is produced below:
<?xml version="1.0" encoding="UTF-8"?>
<EnglishLexRuleSet xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<S id="ateRule" classes="ateClass">
<Subj word="{{msg.data[0]}}"/>
<VP>
<V word="eat"/>
<Obj>
<Number int="{{msg.data[1]}}" isAlpha="true"/>
<N word="apple"/>
</Obj>
</VP>
</S>
</EnglishLexRuleSet>You can call this lex rule by using the realise function:
ATL in Script | Result |
|---|---|
| John eats 2 apples. |
| John and Carol eat one apple. |
The lex rule was able to output the correct subject-verb agreement by itself!
Please note that realise always has at least two parentheses instead of one — e.g. realise((data, class)). This is because the function call itself has a set of brackets and then each of the function's parameters is also wrapped in a set of brackets. Each parameter is a tuple comprising two elements: the first element in the tuple is data (also known as a 'message') and the second identifies the lex rule.
Therefore, a realise call for a tuple like ('Bill', 'StringInput') has 'Bill' as the data or 'message', and 'StringInput' is the value of 'classes' in the opening XML tag of the lex rule. The call is written as [[realise(('Bill','StringInput'))]].
However, when the data or message is itself a list contained in brackets such as ('John', 2), as in our first example above, the realise call will look like [[realise((('John',2),'ateClass'))]].
The data/message part of the tuple can be a variable name. For example, if People is a user-defined variable containing the list "Carol, John, Anne", the ATL [[realise(((People,7),'ateClass'))]] produces the following result:
Carol, John and Anne eat seven apples.
Alternatively, the data/message part of the tuple can be a variable referring directly to JSON data. For example, the downloadable Subject-Verb Agreement JSON project (see link at the top of the page) uses this JSON data:
{
"appleEaters": [
{
"person": "Carol",
"consumed": 2
},
{
"person": "John",
"consumed": 1
},
{
"person": "Anne",
"consumed": 9
}
]
}In that project, using the ATL [[realise(((WholeJSON.appleEaters[0].person,WholeJSON.appleEaters[0].consumed),'ateClass'))]] produces the following result:
Carol eats two apples.
Don't worry! We show you how to use JSON data with lex rules in more detail in the Sentence aggregation section.
The second element in a tuple given to the realise call is the value of the 'classes' attribute in the opening tag of the appropriate lex rule — e.g. "ateClass" in <S id="ateRule" classes="ateClass">.
You can pass more than one tuple into a realise call and thus produce more than one sentence. For example, the ATL [[realise((('Douglas',1),'ateClass'),(('Carol',2),'ateClass'))]] produces the following result:
Douglas eats one apple. Carole eats two apples.
Note
A lex rules file can contain more than one lex rule, and a project can have more than one lex rules file.
For more information about the various kinds of data, you can input to lex rules with the realise function, see More on the realise function.
Let's take a closer look at the lex rule that generates the above sentences. In this case, it is a sentence rule and the opening tag is <S id="ateRule" classes="ateClass"> in which the value of 'classes' is used as the second parameter in the realise function:
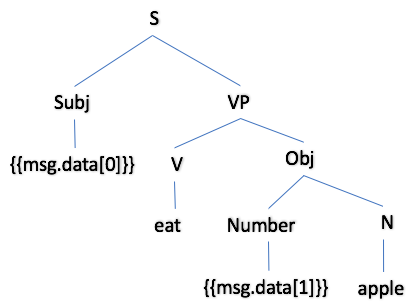 |
<S id="ateRule" classes="ateClass">
<Subj word="{{msg.data[0]}}"/>
<VP>
<V word="eat"/>
<Obj>
<Number int="{{msg.data[1]}}" isAlpha="true"/>
<N word="apple"/>
</Obj>
</VP>
</S>
If you are familiar with sentence analysis, you will recognize that the above lex rule is like a parse tree but written in XML and laid out with indentations. The parse tree, drawn in the normal way, is shown above. The labels are abbreviations as follows: S = sentence, Subj = subject, VP = verb phrase, Obj = object, Number = number, N = noun and {{msg.data[n]}} = a data item.
The lex rule accesses elements in the input data list using the special syntax {{msg.data[n]}}, where n is the index of the element in the list. So {{msg.data[0]}} in the subject is e.g. 'John' and {{msg.data[1]}} the number in the object is 2.
Let's look in more detail at what happens when the first input data item is processed:
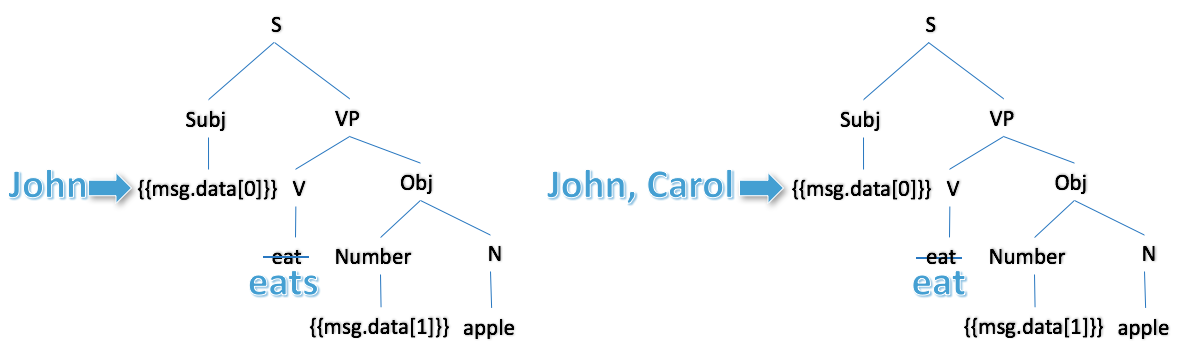 |
We get subject-verb agreement! In the diagram on the left, the first data item is singular ('John') so the verb is inflected as 'eats'. In the diagram on the right, the first data item is plural ('John', 'Carol') so the verb is inflected as 'eat'.
Modifier-noun agreement
Did you notice that the above lex rule also pluralizes the noun "apple" to agree with the second input data item, the number of apples. Let's look in more detail at the modifier-noun agreement that happens automatically when the second data item is processed:
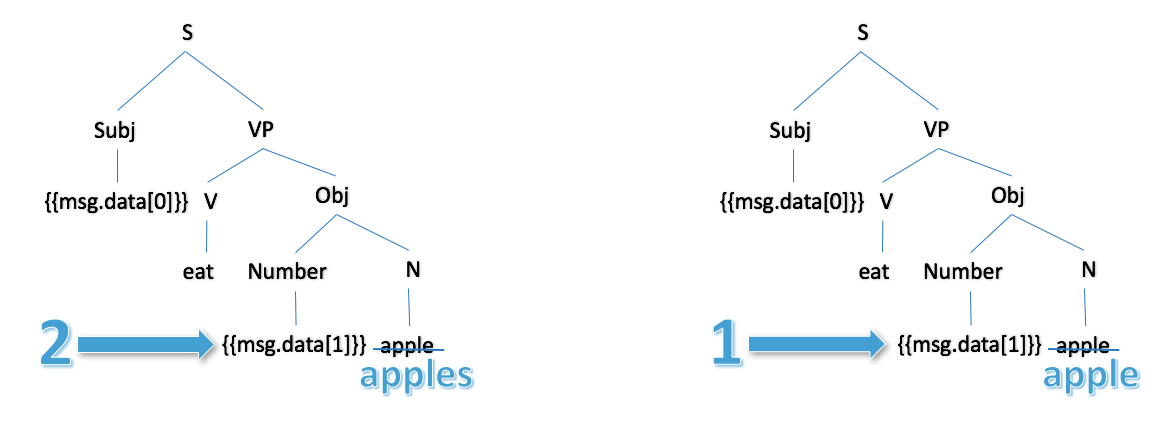 |
When 2 is input to the lex rule as shown on the left, the output is "two apples". When 1 is input as shown on the right, the output is "one apples".
Tip
Modifier-noun agreement can also be handled by the ATL countable function. For example, the ATL [[countable(1,'','apples','')]] produces "one apple".
Exercise
For this exercise, you must download and unzip our Subject-Verb Agreement JSON project for this section of the tutorial. Import the project file into your Project Portal. Open the project, then click Lex Rules (left side menu) to view the XML code for the above lex rule.
If you preview the Main script, you will see the results of generating individual sentences from the rule. Try changing the JSON data and/or the calls to the realise function and view the effects on the output in Preview.
Note
Did you notice that the lex rule also automatically handles agreement between the input number and the noun "apple" (i.e. "apple" is automatically pluralized)?
What you learned in this section
How to do subject-verb agreement in ATL.
How to call a lex rule with the realise function.
What a lex rule looks like in XML.
How to input data to a lex rule.
How to use a lex rule for subject-verb and modifier-noun agreement.
Next, we'll show you how to use lex rules with JSON data for multi-sentence planning.
