Sentence aggregation
This first section demonstrates one way to use lex rules for planning multiple sentences. We demonstrate how to highlight similarities and differences between the content of sentences. You will learn how to automatically aggregate sentences — that is, to join two or more similar sentences together.
Note
This section the tutorial is also available as a downloadable project.
Sometimes the sentences you generate from your JSON data can look very similar. For example:
Peter Jones works in New York. Anna Smith works in New York.
This is too repetitive! Aggregating sentences helps to avoid this repetition. For example:
Peter Jones and Anna Smith work in New York.
Let's go through an example. The JSON data we’ll use is:
{
"employees": [
{
"name": "Peter Jones",
"job": "Head of Innovation",
"teamSize": 1,
"location": "New York"
},
{
"name": "George Scott",
"job": "Head Janitor",
"teamSize": 2,
"location": "New York"
},
{
"name": "Anna Smith",
"job": "Head of Marketing",
"teamSize": 12,
"location": "New York"
},
{
"name": "Sue Collins",
"job": "Chief Software Developer",
"teamSize": 15,
"location": "London"
}
]
}And we’ll use the following lex rule:
<S id="officeId" classes="officeClass">
<Subj word="{{msg.name}}">
<Feature name="surface_aggregatable" value="true"/>
</Subj>
<VP word="work"/>
<Obj string="{{msg.location}}" preposition="in"/>
</S>Important
Lex rules should be inside a lex rules file, as shown here.
An equivalent parse tree for the lex rule is shown below:
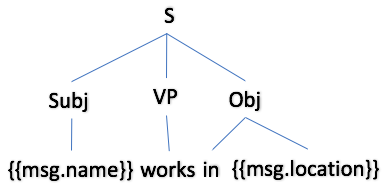 |
In this lex rule, there is a new feature: <Feature name="surface_aggregatable" value="true"/>. Because the feature is added inside the subject (i.e. inside the Subj tags) it enables the subjects of sentences generated by this rule to be aggregated.
JSON data values are accessed in the lex rule with "{{msg.name}}" and "{{msg.location}}". This time, the keys (“name” and “location”) of the JSON values are used instead of "{{msg.data}}" that we saw in the last section, Subject-verb agreement.
To generate one sentence from the lex rule, use the realise function:
ATL in Script | Result |
|---|---|
| Peter Jones works in New York. |
Remember that the realise function’s parameter is a tuple. This time the tuple contains the first element of the WholeJSON array "employees" (the element with Peter Jones’s data) and the value of "classes" specified in the opening tag of the lex rule, officeClass.
Now we’ve seen that the lex rule works with one person’s data. Let’s use it to generate sentences for the entire array. First, let’s do this one sentence at a time (without aggregation) using the forAll function:
ATL in Script | Result |
|---|---|
| Peter Jones works in New York. George Scott works in New York. Anna Smith works in New York. Sue Collins works in London. |
The forAll function goes through the JSON employees array and applies the realise function to each element in the array. The result is four sentences, one for each person’s data.
Next, we’ll call realise with the entire "employees" array:
ATL in Script | Result |
|---|---|
| Peter Jones, George Scott and Anna Smith work in New York. Sue Collins works in London. |
This time, we are producing sentences for all array elements in a single call to realise. The result now has only two sentences. The subjects of the first three sentences have been aggregated because, apart from their subjects, these sentences are identical. Notice that the verb "work" has been correctly inflected for a plural subject.
The effect of aggregation is to highlight the similarities between the first three people (they all work in New York) and the differences between them and the fourth person (who works in London).
The image below shows the result of aggregating the first three sentences as a parse tree.
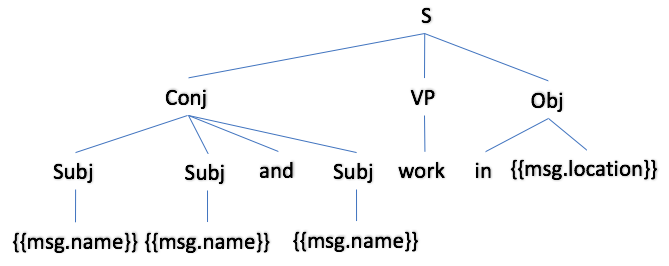 |
Note
Aggregation will occur only when the following conditions are true:
The sentences are adjacent.
The sentence components to be aggregated have the feature
<Feature name="surface_aggregatable" value="true"/>.The other components of the sentences are identical.
This means sentences such as “John ate an apple.”, “Peter ate an apple”, and “Mary ate an apple.” can be aggregated to form “John, Peter and Mary ate an apple.” The sentences “John ate an apple.”, “Peter ate a banana”, and “Mary ate an apple.” will not be aggregated because the apple-eating sentences are not adjacent.
Exercise
For this exercise, you must download and unzip our Sentence Aggregation JSON project for this section of the tutorial. Import the project file into your Project Portal. Open the project, then click Lex Rules (left side menu) to view the XML code for the above lex rule.
If you preview the Main script, you will see the results of generating individual sentences and aggregated sentences from the rule. Try changing the JSON data and/or the calls to the realise function and view the effects on the output in Preview.
Your challenge is to do the following:
Add another key-value pair to each element of the JSON array as follows:
Index
Key-Value Pair
0
"hobby": "golf"1
"hobby": "painting"2
"hobby": "painting"3
"hobby": "traveling"Write another lex rule with a subject the same as the existing one. The rule should generate sentences such as “Peter Jones likes painting.”
Add a realise function to Main to generate sentences from your new lex rule and the entire “employees” array with aggregation. For example, if the value for
classesin your rule is “hobbyClass”, your function would be:[[realise((WholeJSON.employees,"hobbyClass"))]]Preview the output and you should get:
Peter Jones likes golf. George Scott and Anna Smith like painting. Sue Collins likes traveling.
Tip
If you get stuck, download our solution JSON project.
Unzip it, upload it, and view the JSON data, lex rules and ATL code as above.
What you learned in this section
How to turn on aggregation in a lex rule.
How to access JSON data values in a lex rule.
How to call the
realisefunction on one element of a JSON array.How to process elements in a JSON array one at a time.
How to call the
realisefunction on an entire JSON array.How aggregation highlights similarities and differences between the contents of sentences.
Next, we show you another way to plan multiple sentences: subject elision.
